
How We Prevent MTPE from Degrading Translation Memories
This happens because translation memories quietly accumulate the results of thousands of MTPE decisions.
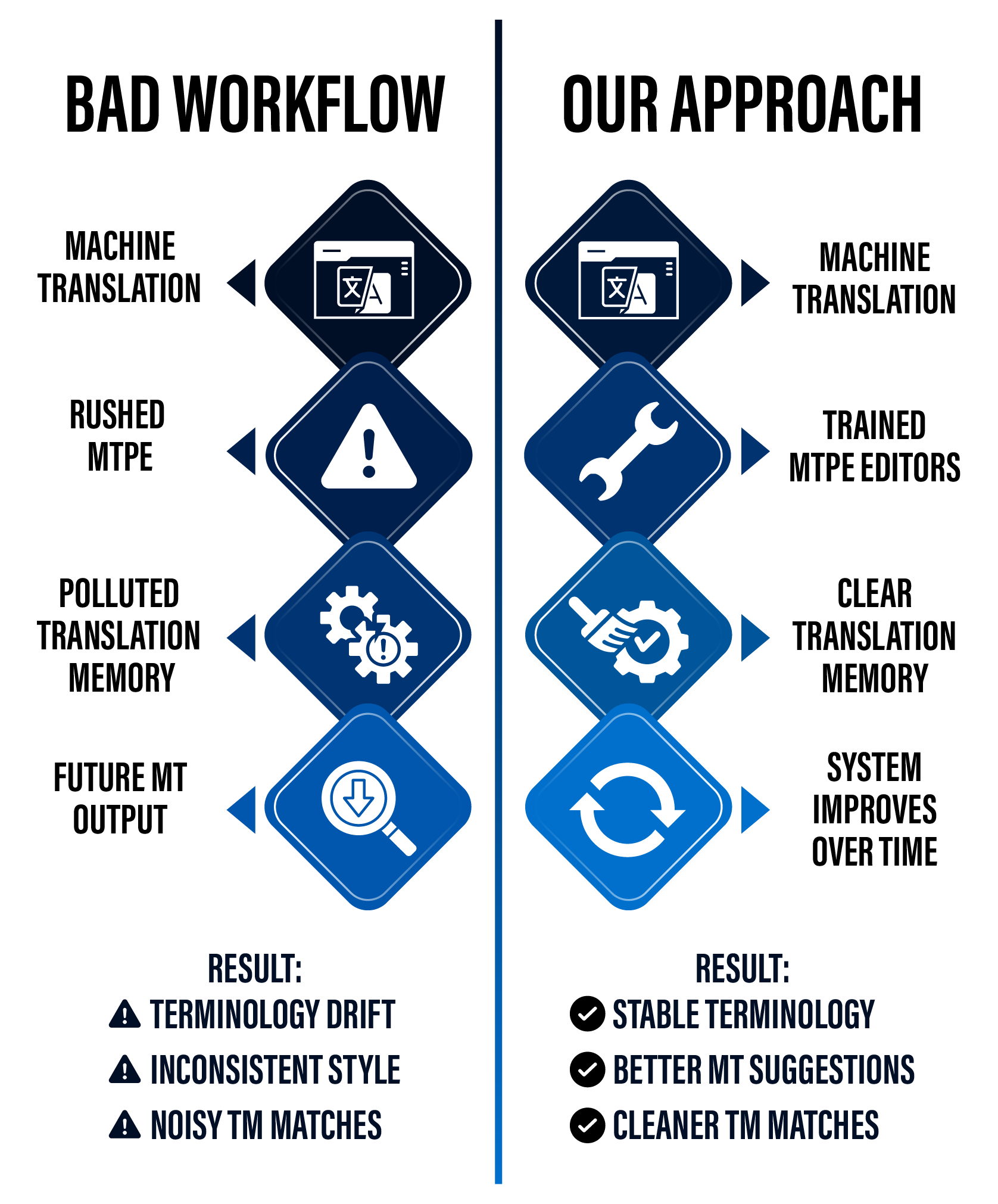
In our previous note we mentioned a problem that many MTPE workflows eventually face: errors introduced during post‑editing often end up stored in translation memories.
At first everything looks fine. Projects are delivered, the output reads well enough, and the system appears to work.
But months later inconsistencies start appearing in places that previously worked well. Terminology drifts, style becomes uneven, and segments that once looked correct start requiring unexpected corrections.
That is why our MTPE training focuses not only on correcting machine output, but also on protecting the long‑term quality of the translation memory.

What Editors Are Trained to Look For
Our editors are trained to recognize common patterns that appear in machine translation output, including:
- grammatical artifacts produced by MT
- terminology drift introduced by machine suggestions
- syntactic structures that appear correct but weaken the translation memory
- unnecessary literal corrections that add noise to future matches
The objective is not simply to make the segment read correctly, but to ensure that the version stored in the translation memory remains useful for future projects.

Data‑Driven Feedback
We periodically analyze MTPE output to identify recurring patterns in both machine errors and editing behavior. Even simple statistical analysis allows us to detect areas where the MT engine repeatedly produces the same type of correction.
This information is used to refine editing guidelines and reduce the amount of noise that enters the translation memory over time.

The Goal
The goal of this approach is simple: ensure that every MTPE project improves the linguistic assets used in future projects instead of slowly degrading them.
Contact Us
If your team is currently working with MTPE workflows for Spanish and would like to compare approaches, we would be happy to exchange notes.
How We Prevent MTPE from Degrading Translation Memories
In our previous note we mentioned a problem that many MTPE workflows eventually face: errors introduced during post‑editing often end up stored in translation memories.
At first everything looks fine. Projects are delivered, the output reads well enough, and the system appears to work.
But months later inconsistencies start appearing in places that previously worked well. Terminology drifts, style becomes uneven, and segments that once looked correct start requiring unexpected corrections.
This happens because translation memories quietly accumulate the results of thousands of MTPE decisions.
What Editors Are
Trained to Look For
Our editors are trained to recognize common patterns that appear in machine translation output, including:
- grammatical artifacts produced by MT
- terminology drift introduced by machine suggestions
- syntactic structures that appear correct but weaken the translation memory
- unnecessary literal corrections that add noise to future matches
The objective is not simply to make the segment read correctly, but to ensure that the version stored in the translation memory remains useful for future projects.
Data‑Driven Feedback
We periodically analyze MTPE output to identify recurring patterns in both machine errors and editing behavior. Even simple statistical analysis allows us to detect areas where the MT engine repeatedly produces the same type of correction.
This information is used to refine editing guidelines and reduce the amount of noise that enters the translation memory over time.
The Goal
The goal of this approach is simple: ensure that every MTPE project improves the linguistic assets used in future projects instead of slowly degrading them.
Contact Us
If your team is currently working with MTPE workflows for Spanish and would like to compare approaches, we would be happy to exchange notes.
